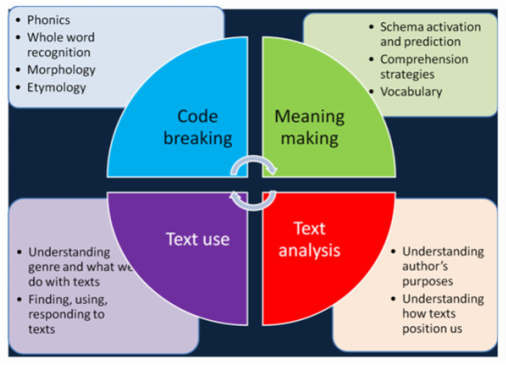
"In 1990 we developed the four resources model of reading (Freebody, 1992; Freebody & Luke, 1990). The model posits four necessary but not sufficient “roles” for the reader in a postmodern, text-based culture:
- Code breaker (coding competence)
- Meaning maker (semantic competence)
- Text user (pragmatic competence)
- Text critic (critical competence)
Expanding the four resources model: reading visual and multi-modal texts Frank Serafini
Abstract
Freebody and Luke proffered an expanded conceptualization of the resources readers utilize when reading and the roles readers adopt during the act of reading. The four resources model, and its associated four roles of the reader, expanded the definition of reading from a simple model of decoding printed texts to a model of constructing meaning and analysing texts in sociocultural contexts. This article continues the reconceptualization of the four resources model to four resources or social practices for reading–viewing multi-modal texts. Drawing on research and theories from visual culture, semiotics, critical media studies, grammars of visual design and multi-modal analysis, the expanded four resources or social practices are reader-viewer as (1) navigator, (2) interpreter, (3) designer and (4) interrogator. Each resource-practice is described in detail and the interpretive repertoires required of reader-viewers transacting with multi-modal texts from each perspective are considered.
Keywords
Freebody and Luke (1990) proffered an expanded conceptualization of the resources readers utilize and the roles readers adopt during the act of reading. The four resources model and its associated four roles of the reader expanded the definition of reading from a simple model of decoding printed texts (Gough, 1972) to a model of constructing meaning and analysing texts in sociocultural contexts (Gee, 1996). The goal was to shift the focus from trying to find the right method for teaching children to read to determining whether the range of resources available and the strategies emphasized in a reading programme were indeed covering and integrating the broad repertoire of practices required in today's economies and cultures (Luke & Freebody, 1999).
The four resources model has been used as a foundation for curriculum reform (Ludwig, 2003), a theoretical framework to broaden educators' understanding of literacy and reading (Freebody, 1992), and as a socio-constructivist critique of the dominance of cognitive perspectives on literacy education and instructional practices (Luke, 1995). The four resources model – which originally included the following four roles of (1) reader as code breaker, (2) reader as text participant, (3) reader as text user and (4) reader as text analyst – provided literacy educators, researchers and theorists with an expanded perspective on what it means to be a successful reader in new times (Freebody & Luke, 1990). Readers were expected to draw upon various resources available to develop and sustain the four roles necessary to be a successful reader. These four roles have taken on a life of their own throughout educational communities irrespective of the authors' original intentions.
In later reiterations of the four resources model, Luke and Freebody (1997, 1999) revised their original concept of the roles readers were to adopt from predetermined ways of acting and thinking that can be defined a priori for particular readers to fit into, to a set of resources or social practices that readers draw upon to make sense of their worlds. This reconceptualizing of the four roles or resources as social practices suggests these roles are constructed rather than adopted, developed in the context of reading rather than taken on as predetermined sets of cognitive skills performed in everyday classrooms, negotiated among practitioners and redeveloped, recombined and articulated in relation to one another on a continuing basis (Luke & Freebody, 1999). The shift from resources and roles to social practices foregrounded how literacy is tied up with political and cultural contexts, social power and capital (Street, 1984). Successful readers should be described in terms of the civil, sociocultural and job demands and expectations that any particular culture places on its members in terms of the degree to which and the ways in which they deal with written text, rather than on the accumulation of cognitive strategies or operations they can perform as individuals. These four resources or social practices are embedded within each other and have been conceptualized as necessary but insufficient for being fully literate in today's society (Freebody & Luke, 1990). In other words, none of the four resources or associated social practices is mutually exclusive or sufficient in and of themselves to create an informed, literate citizenry.
The concept of text throughout the original articulations of the four resources model was primarily focused on printed text and written language. The word text was originally associated with each of the four roles and resources (code breaker or text decoder, text participant, text user, text analyst) and generally referred to print-based materials, although digital and visual texts were not specifically excluded. The first role or resource, reader as code breaker, focused on readers' abilities to decode written text, focusing on sound–symbol relationships and correspondence, not on the interpretation or comprehension of visual images or multi-modal designs. Henderson (1992) described the role as code breaker as “proficient users of the technology of the written script” (p. 124). In addition, Walsh (2006) states, “while there have been different, and often controversial, definitions of reading in the field of education these have been traditionally applied to the reading of print-based and mostly monomodal texts” (p. 25).
In other discussions of the four resources model, Freebody and Luke (2003) acknowledge the multi-modal nature of texts and the importance of digitally based literacies when they state: “To be literate is to be an everyday participant in literate ‘societies’, themselves composed of a vast range of sites, locations and events that entail print, visual, digital and analogue media” (p. 53). Other educators (Anstey & Bull, 2004; Zammit & Downes, 2002), to name but a few, have expanded the concept of text to include digitally based, multi-modal elements combined with traditional print-based texts. As the concept of text expands beyond the borders and boundaries of the printed book, so too must our definitions and conceptions of what it means to be a reader or literate being.
Freebody (2007) suggests the original intention of the four resources model “was to provide an accessible and inclusive framework for discussions of literacy education, while at the same time affording a range of pedagogical strategies and frameworks for teaching literacy and for understanding various disciplines' orientations to literacy education” (p. 35). In the same publication, Freebody (2007, p. 34) continues to use the terms written language and text without specifically referring to screen-based, digital or multi-modal texts on a chart outlining the four roles of the reader. Although I believe his intention was not to ignore the multi-modal aspects of contemporary texts, the terms visual and multi-modal were not included in this description of the model. In further reading of Luke and Freebody's work and various members of the New London Group, Kress (2003, 2010), in particular, supports the idea that Luke and Freebody envisioned multi-modality as an important aspect of the texts readers encounter in today's world, though a definition of text as a multi-modal entity was not directly stated in the original conceptualization of the four resources model.
My intentions are not to find fault with the work of Freebody and Luke, nor lessen the impact or importance of the four resources model. I have nothing but the utmost respect for their work and believe the four resources model has been a vital step forward in expanding the understandings of literacy educators worldwide. My premise is that articulating an expanded conception of the four resources model that specifically addresses the challenges and possibilities that multi-modal texts bring to literacy education is worthy of delineation.
In this article, my intentions are to expand the concept of the four resources model of reading to four resources or social practices for reading–viewing multi-modal texts. In addition, I want to expand the notion of text to address the multi-modal aspects of communication and to include research and theories from visual culture (Barnard, 2001), semiotics (Scholes, 1982; Smith-Shank, 2004), critical media studies (Semali, 2003), grammars of visual design (Kress & van Leeuwen, 1996) and multi-modal analysis (Baldry & Thibault, 2006; Bateman, 2008; Jewitt, 2009).
To expand the original concept of the four resources model, one must reconceptualize the reader as a reader-viewer attending to the visual images, structures and designs of multi-modal texts along with printed text. Although the focus has shifted from printed, mono-modal texts to multi-modal texts throughout the later iterations of the four resources model by numerous educators working from Luke and Freebody's original framework, making the resources and social practices readers draw upon more explicitly focused on visual and multi-modal aspects of screen-based and printed texts alike is an important consideration. Unsworth and Wheeler (2002) assert that if children are to understand how images represent and construct meaning, they need knowledge of the visual meaning-making systems used in their production and interpretation.
In order to create an informed, literate citizenry, readers must be able to navigate, interpret, design and interrogate the written, visual and design elements of multi-modal texts. Cognitively based reading comprehension strategies (Pressley & Block, 2001; Snow & Sweet, 2003) alone will not provide a sufficient foundation for dealing with the various modes of representation incorporated in the multi-modal texts readers encounter in today's world. Theories and research outside the traditional discipline of reading or literacy education should be drawn upon to expand the strategies and skills reader-viewers need to be successful in reading the textual, visual and design elements of the multi-modal texts they encounter.
The goal of this article is not to suggest a failure on the part of Luke and Freebody to adequately address the visual and multi-modality in their original conceptions; rather it is to follow their line of inquiry and continue the expansion of their work to focus on the changing nature of the texts readers encounter in contemporary settings and to expand our vision of reading to include visual images and design elements, in addition to written language. The re-conceptualized four resources or social practices I propose are reader-viewer as (1) navigator, (2) interpreter, (3) designer and (4) interrogator. I will describe each resource-practice and reconsider the actions, abilities and interpretive repertoires required of reader-viewers transacting with multi-modal texts from these perspectives.
Although reading multi-modal texts requires readers to be both readers of written language and viewers of visual images and design elements, I will use the traditional term reader throughout the article rather than the more cumbersome reader-viewer to connote the bifurcated role of the reader and viewer of multi-modal texts.
A shift to multi-modal texts
Contemporary educators and literacy theorists have described a shift from the primacy of the printed word to the visual image and the multi-modal text (Anstey & Bull, 2006; Kress, 2003). Readers are confronted with multi-modal texts that include visual images and a variety of graphic design elements in their everyday lives with greater frequency than texts that are exclusively made of written language (Fleckenstein, 2002). However, multi-modal texts and print-based texts should not be viewed as mutually exclusive. Printed texts often include visual components, for example, font and design elements, and multi-modal texts generally include written language. In addition, readers continue to interact with traditional print-based texts that contain multi-modal elements, for example, picture books, informational texts, magazines and newspapers, and contemporary multi-modal texts that contain visual images, hypertext, video, music, sounds and graphic designs. In fact, most written texts in current social and textual contexts are accompanied by visual images (Kress & van Leeuwen, 2001).
Simply put, a multi-modal text is a text composed of more than one mode. Photography, music, sculpture and written language are examples of different modes. A mode is a system of signs created within or across various cultures to represent and express meanings. Modes were developed by humans to express ideas and communicate with one another. In other words, when more than one mode is present in a text, we consider the text to be multi-modal.
Written language is often subordinate to visual images as the primary mode that readers draw upon to construct meaning (Kress, 2010). Street signs, posters, billboards, websites and contemporary picture books place a primacy on the visual elements readers transact with to construct meanings. A novel which contains little or no visual images or cover art draws primarily on written language to convey meaning. Even in this rare scenario, the text of a novel must be presented in visual form through the application of a particular font and typographic design. Essentially, from this perspective all texts are multi-modal, some more notably than others.
Multi-modal texts present information across a variety of modes including visual images, design elements, written language and other semiotic resources. These texts present challenges to novice readers as they work across these multiple sign systems to construct meaning (Siegel, 2006). The mode of written language and that of visual image are governed by distinct logics: written text is governed by the logic of time or temporal sequence, whereas visual image is governed by the logic of spatiality, organized arrangements and simultaneity (Kress, 2003). In written text, meaning is derived from position in the temporal sequence, and meaning is derived in visual images from spatial relations or visual grammar (Kress & van Leeuwen, 1996).
Using a semiotic perspective as a lens for understanding the ways in which students construct meaning with multi-modal texts, researchers have begun to expand their vision of what it means to be literate and to endorse the significant role that visual literacy plays in contemporary classrooms (Arizpe & Styles, 2003; Callow, 1999; Sipe, 1998). The blending of visual design elements, images and written language into multi-modal texts presents readers with new challenges and requires an expansion of our view of the resources and interpretive practices readers draw upon to make sense of multi-modal texts.
Humans participate in interactions more expansive than language alone can account. “The visual and verbal … are dimensions of the psyche and culture that are closely interconnected” (Seppanen, 2006, p. 6). In addition, readers must also learn to interrogate the assumptions that are embedded within multi-modal texts (Albers, 2008). In order to provide support for these interpretive practices, teachers need theoretical frameworks, new vocabularies or metalanguage and pedagogical strategies for teaching students to interpret and interrogate the visual images and designs encountered in multi-modal texts (Zammit, 2007).
Reader as navigator
The term reader as navigator is not new in research and discussions concerning hypertext and online resources (Lawless & Schrader, 2008). However, the term has not been used as frequently in reference to readers reading traditional print-based, multi-modal texts. When used in reference to reading printed text, the definition of the term navigator presented here subsumes several processes or abilities often associated with reading proficiency, such as decoding, concepts of print, directionality and sequencing. In a broader sense, navigation means to move through space; in terms of hypertext, navigation includes movement through both cognitive and virtual space (Whitaker, 1998). Lawless and Schrader (2008) use the term navigation as a metaphor to describe how readers interact with hypermedia texts. This term can be extended to include digital and print-based, multi-modal texts as well. Readers navigate print-based multi-modal texts (e.g. textbooks or picture books) and screen-based multi-modal texts based on their purposes for reading and the meanings readers construct in their transactions with these texts.
The research on the decoding of written texts refers to a series of cognitive strategies or skills, including word recognition, vocabulary knowledge, sound (phoneme) to symbol (grapheme) correspondence and the recognition of patterns in spelling and language to be successful (Bear, Invernizzi, Templeton, & Johnston, 2000; Dahl, 2001; Moustafa, 1997). When reading multi-modal texts, the skill of decoding written text needs to be accompanied by an understanding of the structures and codes associated with design, images and other visual elements (Kress & van Leeuwen, 1996). In addition to decoding written language, readers must learn to navigate the design of written text, including the left to right orientation of English language texts, and understand the role and structures of charts, graphs, diagrams and other visual images encountered in picture books, informational texts, graphic novels, websites, advertisements and other multi-modal texts.
In contrast to the temporal nature of the written language, there is no preset or determined path that readers are required to follow sequentially through multi-modal texts (Kress, 2003). Readers actively select objects from their visual field to attend to and interpret. A particular multi-modal text or visual image may contain compositional structures that lead a viewer's eye in certain directions, and certain features of visual grammar – for example, modality, framing and salience (Kress & van Leeuwen, 1996) – may draw one's attention to particular aspects of an image or multi-modal text; however, the reading path is ultimately determined by the readers during their transaction with the spatial composition of the text.
Focusing on visual images, Beardsley (1981) suggested:
a picture is two things at once: it is a design, and it is a picture of (italics in original) something. In other words, it presents something to the eye for direct inspection, and it represents something that exists, or might exist outside the picture frame. (p. 267)
What is presented to the eye for direct inspection or close attention are the literal or natural aspects of an image (Panofsky, 1955). Naming the visual elements of a multi-modal text, and taking an inventory of its contents, is primarily a perceptual act (Serafini, 2010). Readers navigating multi-modal texts must attend to, or perceive, what has been rendered by the artist, illustrator, publisher or graphic designer. The successful navigation of multi-modal texts is an important precursor of the interpretation of these texts.
Navigating multi-modal texts requires readers to attend to the grammars of visual design, in addition to the grammar, structures and typography associated with written language. The decoding processes outlined by Luke and Freebody (1999), for instance, delineate a reader's ability to break the code of written texts by recognizing and using fundamental features and architecture, including alphabet, sounds in words and spelling, and structural conventions and patterns may be subsumed within the larger concept of navigating. In addition, non-linear structures, hypertext, visual images and multi-modal compositional structures need to be navigated by readers if readers are to be successful in today's educational settings. Navigating, including the decoding of written text, is an important skill and an equally important consideration for literacy educators, but it is an insufficient skill in and of itself to make readers proficient in new times.
Reader as interpreter
Simply stated, readers as interpreters are readers engaged in the act or process of interpretation. Interpretation is a process of constructing or generating viable meanings and responses to various texts and images. Terms such as comprehending, understanding, constructing meaning and making sense are often used interchangeably to define the act of interpretation. Whatever term is selected, one of the primary goals of reading a multi-modal text or viewing a visual image is to understand or comprehend what has been written by the author or depicted by the artist (Goodman, 1996; Kress & van Leeuwen, 1996).
Interpretation is a contested concept. Various literary theories rely on different methods or processes of interpretation “because each has a different metaphysics, a different set of convictions that makes up its point of departure and defines its position in the hermeneutic field” (Armstrong, 1990, p. 4). Debates between monists, theorists that assert single, correct interpretations of a literary work discoverable by appealing to authorial intentions or close readings of the work itself, and pluralists, theorists that insist any text allows for an infinite array of legitimate readings, have challenged the notion of comprehension as an objective enterprise. If one aligns with Rorty's (1979) contention that there exists no single truth but always an array of interpretations, comprehension must be reconsidered as an act of interpretation, not as one of discovery of a single meaning or truth that exists a priori to the act of reading. The monist and pluralist theoretical positions may be incommensurable, but each relies on particular epistemological moves to “give momentary stability and coherence to what is dynamic, contradictory, and historical” (Solsken, 1993, p. 319).
Writing about Luke and Freebody's four resources model, Ludwig (2003) chooses the preposition from when describing the reader as text participant. She writes, “the emphasis is on comprehending and composing or making meaning from written, spoken, visual and multi-modal texts” (p. 1). The preposition from assumes that meaning is interred within the text and a meaning is discovered that exists a priori to the act of reading. Often times, the use of the preposition from connotes an objectivist conception of meaning, assuming meaning exists before the act of reading takes place and is to be discovered by the reader (Serafini, 2010). The preposition with could be used to connote a more constructivist stance in regard to the act or processes of reading.
In addition, the term comprehension connotes an objective perspective towards meaning making (Smagorinsky, 2001). It may be useful to reconsider the term comprehension (as noun), referring to a commodity or amount of information that is individually acquired through cognitive skill or work, or some measurable amount of knowledge or understanding that is literally taken away from every successful reading event. Instead, it may be more appropriate to consider the term comprehending (as verb), to refer to reading as a process, a recursive cycle of generating meanings that changes each time readers transact with a visual image of multi-modal text across particular contexts. This second definition, comprehending as verb, is closely associated with the concept and process of interpretation presented here. Interpretation is a construction of meaning drawing on one's prior knowledge and experiences the immediate and cultural contexts of the act of reading and the language and images presented for interpretation (Scholes, 2001).
Based on these theoretical assertions, readers should no longer be viewed as solitary explorers trying to uncover a single main idea hidden in the bowels of a classic novel or as “passive consumers of authoritative interpretations” (Faust, 1994, p. 25). Readers should be viewed as active constructors of meanings, transacting with texts in particular times, places and contexts (Rosenblatt, 1978). Readers come to the act of reading with their prior cultural, linguistic, literary and life experiences and draw upon these experiences as each reading is “situated in dialogue with and in extension of other readings” (Smagorinsky, 2001, p. 141). An expanded definition of reader as interpreter needs to address the processes of generating viable interpretations in transaction with visual images and written texts and one's ability to construct understandings from multiple perspectives, including the author's intentions, textual references, personal experiences and sociocultural contexts in which one reads (Serafini & Ladd, 2008).
This shift from comprehension to interpretation assumes an increase in authority or agency of the reader during the reading process. Readers as interpreters are constructors of meanings, drawing upon available resources to make sense of what is written or depicted. This is a shift away from what is referred to as an autonomous model of literacy (Street, 1984) or as a conduit model of reading (Mosenthal, 1987) where meanings exist a priori and are simply presented to readers through a text serving as a neutral channel or conduit.
When considering the images, text and design elements contained in multi-modal texts, it should be made clear that images are not neutral, objective representations of reality anymore than language is a neutral, objective representation of reality (Gombrich, 1961; Rorty, 1979). Viewers of design elements and visual images, like readers of written texts, are socialized into ways of seeing, in much the same way that readers are socialized into particular ways of reading (Berger, 1972).
A visual image, like a written text, does not exist nor is it created in a vacuum. An image, like any written text, “is not a unitary, seamless whole, but can be fragmented and atomized into constituent elements, and these elements represent a life of their own and that of others” (Hartman, 1992, p. 297). Readers draw upon a wide range of experiences with other images and texts during their act of interpretation. The unique personal experiences of each individual reader add to the variations inherent in one's interpretations. In similar fashion, the experiences one has in common with other members of a culture, society or community of readers add to the commonalities of interpretations across individual readers (Fish, 1980).
The process of interpreting multi-modal texts requires readers to draw from their experiential reservoirs to generate viable interpretations to add to the interpretations made by others in a community of readers regardless of one's allegiance to any single literary theory. Freebody's (1992) original conception of reader as text participant included knowledge of “the resources to engage in the technology of the text itself – its meaning and structure” (p. 53) and conceived of the reader as an “inferrer of connections between textual elements and of additional material required to fill out the unexplicated aspects of text” (p. 53). Luke and Freebody (1999) extended their definition of reader as text participant to include participation in understanding and composing meaningful written, visual and multi-modal texts, taking into account each text's interior meaning systems in relation to their available knowledge and their experiences of other cultural discourses, texts and meaning systems.
The interpretation of multi-modal texts requires readers to develop interpretive repertoires that address the visual images and design elements, in addition to the text itself, and the meaning potential across the various modes presented. Drawing on social semiotics (van Leeuwen, 2005), multi-modal analysis (Kress, 2010; Machin, 2007), iconography (Panofsky, 1955) and art theory (Gombrich, 1961), the interpretation of visual images and design can be conceived as a tripartite or three-tiered interpretive framework that requires attention to the perceptual, structural and ideological aspects of multi-modal texts (Serafini, 2010). The images contained in multi-modal texts encountered in complex social contexts are created with particular semiotic resources, basic design elements and visual structures. To expand one's interpretive repertoires to include approaches to visual analysis, readers will be required to synthesize perceptual abilities with structural perspectives and political, historical and cultural understandings. The act of interpreting may focus on the construction of knowledge by individual readers, but must also account for the sociocultural contexts of production, as well as reception, of multi-modal texts.
Reader as designer
Reader as designer extends the constructivist metaphor (Spivey, 1997) or role of reader as text participant to assert that readers of multi-modal texts not only construct meaning from what is depicted or represented, but also design the way the text is read, its reading path, what is attended to and, in the process, construct a unique experience during their transaction with a text. Reader as designer goes beyond the classic constructivist metaphor that asserts readers construct meaning from a text that exists a priori, to suggest readers actually construct the text to be read. From a literary theoretical perspective, this concept of constructing meaning associated with reader as designer goes beyond the reception theory of Iser (1978) and aligns more closely with Fish's (1980) notion of interpretive communities positing there is no immanent meaning in text and suggests readers decide not only what texts mean, but what can be considered a text.
Beginning with James' (1978) notion of selective attention and progressing through contemporary theories of multi-modality (Kress, 2010), a contemporary definition of the term design refers to “the process of translating the rhetor's politically oriented assessment of the environment of communication into semiotically shaped material” (Kress, 2010, p. 132). A general principle of semiosis, in particular a principle of design, is the process of transformation (Kress & van Leeuwen, 2001). Readers design texts to be navigated and interpreted by drawing upon the available semiotic resources presented in a text and construct meanings during the act of reading. Design is the process of organizing what is to be navigated, interpreted and articulated, shaping available resources into potential meanings realized in the context of reading multi-modal texts. In other words, the text to be read does not come to the reader ready-made; the text comes as semiotic potential, where the text to be interpreted is designed during the act of reading.
Up to this point, design has been primarily conceived from the perspective of the writer, creator or rhetor in Kress' terms (Kress, 2010). The designer of a text imagines the task at hand, uses his/her knowledge of available semiotic resources, understands the wider social conditions of production and reception and produces a text by selecting a site of appearance for the materialization of its intended meanings (Kress, 2010). The New London Group (1996) suggested educators “treat any semiotic activity, including language to produce or consume texts, as a matter of Design” (p. 74). Their concept of design involved the transformation, not replication, of available designs, suggesting that meaning is constructed anew in each act of reading (interpreting) or authoring (producing) texts, while at the same time reconstructing and renegotiating the reader's identity. Hull and Nelson (2005) write, “it is obvious how useful the notion of design can become as a way to conceptualize the suddenly increased array of choices about semiotic features that an author confronts” (p. 229). What may not be as obvious is the way that design plays a role in the way a reader constructs the reading paths, the array of choices of semiotic features and, in essence, the texts being read.
The concept of reader as designer can be extended from the producer of texts to the process of navigating and interpreting multi-modal texts as well. Making a shift from designer as producer of multi-modal texts to navigator, interpreter of texts requires an expansion of the concept of design to include the active construction of meaning potentials during reader's transactions with multi-modal texts. Unlike traditional written text that is presented in a linear, temporal sequence, where the reading path is ordered a priori, multi-modal and hypertexts are often presented in non-linear fashion. For example, postmodern picture books (Sipe & Pantaleo, 2008) require readers to not only navigate the visual and textual elements presented during the act of reading, but to actually design the text to be read from the visual and textual elements. Like the traditional “choose your own adventure texts”, the reader is required to become an even more active participant in the navigation, interpretation and design of multi-modal texts.
Numerous reading paths are possible given the compositional nature and spatial arrangements of multi-modal texts (Kress, 2010). However, the paths chosen by readers are not arbitrary, nor are they predetermined by the artist or graphic designer, though these creators draw upon various compositional, visual, design and typographical features to suggest how a text may be read. The interests, needs and experiences of the reader motivate which paths are selected. In this sense, the concept of design provides the reader with agency as he/she constructs meaning from the available semiotic resources presented in the multi-modal text.
Kress and van Leeuwen (2001) suggest contemporary or multi-modal texts ask readers to perform a different semiotic work, namely to design the order of the text or reading path for themselves before interpreting the text constructed. This semiotic work requires readers to make choices about how to frame the text being read. Whereas the process of navigation requires the reader to navigate the design elements of the text presented by the author-illustrator-publisher, the process of design requires the readers to construct their own reading path by framing the elements of a multi-modal text to suit their particular needs and interests during the act of reading. Navigating the elements presented by the author-illustrator-publisher and making decisions about the sequence of elements considered should be considered acts of design, utilizing the semiotic resources available to construct meaning in transaction with the elements of these texts.
As compared with the temporal or linear composition of written language, the spatial composition of visual and multi-modal texts presents readers with a less directed, more open reading path. This openness requires readers to design the path through which their reading occurs. Similar to Rosenblatt's (1978) concept of evocation, the reader of multi-modal texts must evoke or design the text to be read before it can be interpreted. The shift from the dominance of linear, print-based texts to visual and multi-modal texts requires a more active process on behalf of the reader and less authority and direction by the author-illustrator-publisher (Kress, 2010).
An additional aspect of reader as designer is the concept of framing (Kress & van Leeuwen, 1996). Readers construct frames around experience to organize encounters with the world, in particular with multi-modal texts, to make sense of these texts and consider them in the contexts in which they are realized. Without a frame, there is no meaning potential since all meaning is constructed within a discourse or other framing device. Frames mark both temporal and spatial locations. They separate the text being read from the context in which it is read. The reader decides on what is part of the text and what is part of the context to be considered when reading.
Framing devices include, as well as exclude, aspects of the world or text to be considered. The act of framing decides the aspects of the text to be considered in accordance with the interests of the framer (Kress, 2010). In other words, the reader makes decisions about which aspects of the texts are being navigated to consider and interpret and, in doing so, designs the text to be read, rather than passively uncovering a text that comes to the reader ready-made according to the ministrations of the author, illustrator/designer or publisher. For Kress (2010), this is the inherent difference between the world ordered for the reader and the world designed by the reader. The reader as designer selects from all the possible ways of positioning a text, the various design, visual and textual elements presented and the sociocultural contexts of the act of reading and decides on how a particular text is to be read in a particular time and place.
Reader as interrogator
Understanding the social practice of reader as interrogator requires a shift from a primarily cognitive theory of reading (Anderson & Pearson, 1984) to consider cultural theories of meaning (Smagorinsky, 2001). Cultural theories of meaning assume a reading of a text to have idiosyncratic (personal) as well as culturally mediated (public) meanings. From this perspective, reading is re-conceptualized as a social practice that involves the construction of meaning in a socially mediated context, the power relationships inherent in any given setting and the readers' identity and available means of social participation. Although the term interrogator was chosen rather than the term analyst to connote a more aggressive stance to interpreting and designing texts, the two concepts are closely aligned. The concept of interrogator, like that of text analyst, includes the critical and sociocultural aspects of analysis espoused by Luke and Freebody in their original four resources model.
Meanings constructed during the act of reading are socially embedded, temporary, partial and plural (Corcoran, Hayhoe, & Pradl, 1994). Texts are not interpreted by readers in a vacuum, but are always read by particular readers, in particular contexts, written by particular authors, containing an array of semiotic resources, including written language, visual images and design elements (Lewis, 2000). Additionally, different readings, meanings and interpretations have material, discursive and sociocultural consequences for readers. Working from a poststructuralist or critical perspective, the meanings constructed in transaction with multi-modal texts are social, historical, partial, multiple and political (Brodkey, 1992). In other words, if the reading of a multi-modal text requires the text to be framed or designed in a particular way, the text can be framed in other ways and each frame has significant consequences for the reader.
Research from a sociocultural or critical perspective focuses on the types of meanings that readers construct, how these meanings are affected by the social context and reading practices that readers are located within and the purposes of constructing particular responses (Gee, 1992; John-Steiner, Petoskey, & Smith, 1994). Readers construct readings (plural), not as originators of meaning, but as human subjects positioned through social, political and historical practices that remain the location of a constant struggle over power.
Visual grammar, iconology and media studies suggest readers analyse texts at the site of production, image and reception or audience (Rose, 2001). Where cognitive theories of reading focus primarily on the site of reception, the reader as interrogator must consider the production of images and multi-modal texts and the intended audiences for such texts when constructing meanings during the act of reading. “To explore the meaning of images is to recognize that they are produced within a system of social power and ideology. Ideologies are systems of belief that exist within all cultures” (Sturken & Cartwright, 2001, p. 21). They continue, “images are an important means through which ideologies are produced and onto which ideologies are projected” (p. 21). Rose (2001) argues, “one of the central aims of ‘the cultural turn’ in the social sciences is to argue that social categories are not natural but instead are constructed. These constructions can take visual form” (pp. 10–11). The interrogation of the visual images and elements of multi-modal texts, including borders, fonts, graphic design and colour, is just as important as the analysis of the written text.
To understand the images and design elements presented in multi-modal texts requires readers to consider aspects of production and reception, in addition to the aspects of the image and text itself. The capacity of images to affect us as viewers is dependent on the larger cultural meanings they evoke and the social, political and cultural contexts in which they are viewed (Sturken & Cartwright, 2001). Wolcott (1996) argues that readers must look not only at the relationships within a work of art but beyond the work itself to the historical, cultural and social contexts in order to comprehend its meaning.
Moving beyond the literal level of meaning requires readers to infer from various texts and contexts to interrogate what they read and view (Serafini & Ladd, 2008). Every classroom is a site for the production of meaning, and every interpretive community has some alignment with a particular literary tradition or perspective (Fish, 1980). Helping readers interrogate the meaning potential of the semiotic and multi-modal resources of a text is an important consideration in today's educational environment.
Concluding remarks
There are numerous theoretical and pedagogical challenges that arise in expanding the four resources or social practices model for reading multi-modal texts. The first challenge in constructing separate resources or practices is the distinctions between the four new resources or reading practices are blurred. How does one perceive and navigate the visual images and design of multi-modal texts without constructing meaning and having a set purpose for reading? How does a reader design the texts being read without analysing them simultaneously? These four expanded resources, although presented as four distinct resources for reading, are interrelated and inseparable in the act of reading–viewing. Freebody and Luke (1990) stated that each resource or practice was necessary but insufficient and that no single resource was sufficient in and of itself for being successful in today's societies. The same holds true for the four resources described for reading multi-modal texts.
A second challenge is the social practices for reading multi-modal texts themselves do not emerge a priori; these practices are constructed by readers in the same way as the earlier practices were constructed in sociocultural, historical, political and economic contexts. In addition, viewers of images, like readers of written texts, have agency in their creation of these practices and their use of these interpretive and analytic strategies and processes. The four multi-modal practices are adapted, not simply adopted, by readers as they transact with the texts and images in the various contexts in which they are encountered.
A third challenge arises in trying to avoid describing the four resources model hierarchically. Rather than conceptualizing the four resources as a hierarchical set of competencies, the four practices are “nested” within one another, influencing each other and blurring the distinctions between the various perspectives or practices described (Serafini, 2010). Freebody and Luke (2003) consider the four resources model a “systematic way of interrogating practice” (p. 57) with each resource contributing to the reading process in its own unique way.
By expanding the dimensions we bring to interpreting and understanding multi-modal texts, we widen the scope of inquiry to include perceptual and cognitive perspectives, in addition to sociocultural and critical theoretical and analytical perspectives. The power of the four resources model was its inclusion of different theoretical perspectives, not in its exclusion. The role of progressive literacy education is to open up the interpretive spaces we provide through the expectations we set, the responses we endorse and support, the texts we select to expand readers' interpretive repertoires and the strategies we demonstrate during reading instruction (Serafini, 2011).
References
Abstract
Freebody and Luke proffered an expanded conceptualization of the resources readers utilize when reading and the roles readers adopt during the act of reading. The four resources model, and its associated four roles of the reader, expanded the definition of reading from a simple model of decoding printed texts to a model of constructing meaning and analysing texts in sociocultural contexts. This article continues the reconceptualization of the four resources model to four resources or social practices for reading–viewing multi-modal texts. Drawing on research and theories from visual culture, semiotics, critical media studies, grammars of visual design and multi-modal analysis, the expanded four resources or social practices are reader-viewer as (1) navigator, (2) interpreter, (3) designer and (4) interrogator. Each resource-practice is described in detail and the interpretive repertoires required of reader-viewers transacting with multi-modal texts from each perspective are considered.
Keywords
Freebody and Luke (1990) proffered an expanded conceptualization of the resources readers utilize and the roles readers adopt during the act of reading. The four resources model and its associated four roles of the reader expanded the definition of reading from a simple model of decoding printed texts (Gough, 1972) to a model of constructing meaning and analysing texts in sociocultural contexts (Gee, 1996). The goal was to shift the focus from trying to find the right method for teaching children to read to determining whether the range of resources available and the strategies emphasized in a reading programme were indeed covering and integrating the broad repertoire of practices required in today's economies and cultures (Luke & Freebody, 1999).
The four resources model has been used as a foundation for curriculum reform (Ludwig, 2003), a theoretical framework to broaden educators' understanding of literacy and reading (Freebody, 1992), and as a socio-constructivist critique of the dominance of cognitive perspectives on literacy education and instructional practices (Luke, 1995). The four resources model – which originally included the following four roles of (1) reader as code breaker, (2) reader as text participant, (3) reader as text user and (4) reader as text analyst – provided literacy educators, researchers and theorists with an expanded perspective on what it means to be a successful reader in new times (Freebody & Luke, 1990). Readers were expected to draw upon various resources available to develop and sustain the four roles necessary to be a successful reader. These four roles have taken on a life of their own throughout educational communities irrespective of the authors' original intentions.
In later reiterations of the four resources model, Luke and Freebody (1997, 1999) revised their original concept of the roles readers were to adopt from predetermined ways of acting and thinking that can be defined a priori for particular readers to fit into, to a set of resources or social practices that readers draw upon to make sense of their worlds. This reconceptualizing of the four roles or resources as social practices suggests these roles are constructed rather than adopted, developed in the context of reading rather than taken on as predetermined sets of cognitive skills performed in everyday classrooms, negotiated among practitioners and redeveloped, recombined and articulated in relation to one another on a continuing basis (Luke & Freebody, 1999). The shift from resources and roles to social practices foregrounded how literacy is tied up with political and cultural contexts, social power and capital (Street, 1984). Successful readers should be described in terms of the civil, sociocultural and job demands and expectations that any particular culture places on its members in terms of the degree to which and the ways in which they deal with written text, rather than on the accumulation of cognitive strategies or operations they can perform as individuals. These four resources or social practices are embedded within each other and have been conceptualized as necessary but insufficient for being fully literate in today's society (Freebody & Luke, 1990). In other words, none of the four resources or associated social practices is mutually exclusive or sufficient in and of themselves to create an informed, literate citizenry.
The concept of text throughout the original articulations of the four resources model was primarily focused on printed text and written language. The word text was originally associated with each of the four roles and resources (code breaker or text decoder, text participant, text user, text analyst) and generally referred to print-based materials, although digital and visual texts were not specifically excluded. The first role or resource, reader as code breaker, focused on readers' abilities to decode written text, focusing on sound–symbol relationships and correspondence, not on the interpretation or comprehension of visual images or multi-modal designs. Henderson (1992) described the role as code breaker as “proficient users of the technology of the written script” (p. 124). In addition, Walsh (2006) states, “while there have been different, and often controversial, definitions of reading in the field of education these have been traditionally applied to the reading of print-based and mostly monomodal texts” (p. 25).
In other discussions of the four resources model, Freebody and Luke (2003) acknowledge the multi-modal nature of texts and the importance of digitally based literacies when they state: “To be literate is to be an everyday participant in literate ‘societies’, themselves composed of a vast range of sites, locations and events that entail print, visual, digital and analogue media” (p. 53). Other educators (Anstey & Bull, 2004; Zammit & Downes, 2002), to name but a few, have expanded the concept of text to include digitally based, multi-modal elements combined with traditional print-based texts. As the concept of text expands beyond the borders and boundaries of the printed book, so too must our definitions and conceptions of what it means to be a reader or literate being.
Freebody (2007) suggests the original intention of the four resources model “was to provide an accessible and inclusive framework for discussions of literacy education, while at the same time affording a range of pedagogical strategies and frameworks for teaching literacy and for understanding various disciplines' orientations to literacy education” (p. 35). In the same publication, Freebody (2007, p. 34) continues to use the terms written language and text without specifically referring to screen-based, digital or multi-modal texts on a chart outlining the four roles of the reader. Although I believe his intention was not to ignore the multi-modal aspects of contemporary texts, the terms visual and multi-modal were not included in this description of the model. In further reading of Luke and Freebody's work and various members of the New London Group, Kress (2003, 2010), in particular, supports the idea that Luke and Freebody envisioned multi-modality as an important aspect of the texts readers encounter in today's world, though a definition of text as a multi-modal entity was not directly stated in the original conceptualization of the four resources model.
My intentions are not to find fault with the work of Freebody and Luke, nor lessen the impact or importance of the four resources model. I have nothing but the utmost respect for their work and believe the four resources model has been a vital step forward in expanding the understandings of literacy educators worldwide. My premise is that articulating an expanded conception of the four resources model that specifically addresses the challenges and possibilities that multi-modal texts bring to literacy education is worthy of delineation.
In this article, my intentions are to expand the concept of the four resources model of reading to four resources or social practices for reading–viewing multi-modal texts. In addition, I want to expand the notion of text to address the multi-modal aspects of communication and to include research and theories from visual culture (Barnard, 2001), semiotics (Scholes, 1982; Smith-Shank, 2004), critical media studies (Semali, 2003), grammars of visual design (Kress & van Leeuwen, 1996) and multi-modal analysis (Baldry & Thibault, 2006; Bateman, 2008; Jewitt, 2009).
To expand the original concept of the four resources model, one must reconceptualize the reader as a reader-viewer attending to the visual images, structures and designs of multi-modal texts along with printed text. Although the focus has shifted from printed, mono-modal texts to multi-modal texts throughout the later iterations of the four resources model by numerous educators working from Luke and Freebody's original framework, making the resources and social practices readers draw upon more explicitly focused on visual and multi-modal aspects of screen-based and printed texts alike is an important consideration. Unsworth and Wheeler (2002) assert that if children are to understand how images represent and construct meaning, they need knowledge of the visual meaning-making systems used in their production and interpretation.
In order to create an informed, literate citizenry, readers must be able to navigate, interpret, design and interrogate the written, visual and design elements of multi-modal texts. Cognitively based reading comprehension strategies (Pressley & Block, 2001; Snow & Sweet, 2003) alone will not provide a sufficient foundation for dealing with the various modes of representation incorporated in the multi-modal texts readers encounter in today's world. Theories and research outside the traditional discipline of reading or literacy education should be drawn upon to expand the strategies and skills reader-viewers need to be successful in reading the textual, visual and design elements of the multi-modal texts they encounter.
The goal of this article is not to suggest a failure on the part of Luke and Freebody to adequately address the visual and multi-modality in their original conceptions; rather it is to follow their line of inquiry and continue the expansion of their work to focus on the changing nature of the texts readers encounter in contemporary settings and to expand our vision of reading to include visual images and design elements, in addition to written language. The re-conceptualized four resources or social practices I propose are reader-viewer as (1) navigator, (2) interpreter, (3) designer and (4) interrogator. I will describe each resource-practice and reconsider the actions, abilities and interpretive repertoires required of reader-viewers transacting with multi-modal texts from these perspectives.
Although reading multi-modal texts requires readers to be both readers of written language and viewers of visual images and design elements, I will use the traditional term reader throughout the article rather than the more cumbersome reader-viewer to connote the bifurcated role of the reader and viewer of multi-modal texts.
A shift to multi-modal texts
Contemporary educators and literacy theorists have described a shift from the primacy of the printed word to the visual image and the multi-modal text (Anstey & Bull, 2006; Kress, 2003). Readers are confronted with multi-modal texts that include visual images and a variety of graphic design elements in their everyday lives with greater frequency than texts that are exclusively made of written language (Fleckenstein, 2002). However, multi-modal texts and print-based texts should not be viewed as mutually exclusive. Printed texts often include visual components, for example, font and design elements, and multi-modal texts generally include written language. In addition, readers continue to interact with traditional print-based texts that contain multi-modal elements, for example, picture books, informational texts, magazines and newspapers, and contemporary multi-modal texts that contain visual images, hypertext, video, music, sounds and graphic designs. In fact, most written texts in current social and textual contexts are accompanied by visual images (Kress & van Leeuwen, 2001).
Simply put, a multi-modal text is a text composed of more than one mode. Photography, music, sculpture and written language are examples of different modes. A mode is a system of signs created within or across various cultures to represent and express meanings. Modes were developed by humans to express ideas and communicate with one another. In other words, when more than one mode is present in a text, we consider the text to be multi-modal.
Written language is often subordinate to visual images as the primary mode that readers draw upon to construct meaning (Kress, 2010). Street signs, posters, billboards, websites and contemporary picture books place a primacy on the visual elements readers transact with to construct meanings. A novel which contains little or no visual images or cover art draws primarily on written language to convey meaning. Even in this rare scenario, the text of a novel must be presented in visual form through the application of a particular font and typographic design. Essentially, from this perspective all texts are multi-modal, some more notably than others.
Multi-modal texts present information across a variety of modes including visual images, design elements, written language and other semiotic resources. These texts present challenges to novice readers as they work across these multiple sign systems to construct meaning (Siegel, 2006). The mode of written language and that of visual image are governed by distinct logics: written text is governed by the logic of time or temporal sequence, whereas visual image is governed by the logic of spatiality, organized arrangements and simultaneity (Kress, 2003). In written text, meaning is derived from position in the temporal sequence, and meaning is derived in visual images from spatial relations or visual grammar (Kress & van Leeuwen, 1996).
Using a semiotic perspective as a lens for understanding the ways in which students construct meaning with multi-modal texts, researchers have begun to expand their vision of what it means to be literate and to endorse the significant role that visual literacy plays in contemporary classrooms (Arizpe & Styles, 2003; Callow, 1999; Sipe, 1998). The blending of visual design elements, images and written language into multi-modal texts presents readers with new challenges and requires an expansion of our view of the resources and interpretive practices readers draw upon to make sense of multi-modal texts.
Humans participate in interactions more expansive than language alone can account. “The visual and verbal … are dimensions of the psyche and culture that are closely interconnected” (Seppanen, 2006, p. 6). In addition, readers must also learn to interrogate the assumptions that are embedded within multi-modal texts (Albers, 2008). In order to provide support for these interpretive practices, teachers need theoretical frameworks, new vocabularies or metalanguage and pedagogical strategies for teaching students to interpret and interrogate the visual images and designs encountered in multi-modal texts (Zammit, 2007).
Reader as navigator
The term reader as navigator is not new in research and discussions concerning hypertext and online resources (Lawless & Schrader, 2008). However, the term has not been used as frequently in reference to readers reading traditional print-based, multi-modal texts. When used in reference to reading printed text, the definition of the term navigator presented here subsumes several processes or abilities often associated with reading proficiency, such as decoding, concepts of print, directionality and sequencing. In a broader sense, navigation means to move through space; in terms of hypertext, navigation includes movement through both cognitive and virtual space (Whitaker, 1998). Lawless and Schrader (2008) use the term navigation as a metaphor to describe how readers interact with hypermedia texts. This term can be extended to include digital and print-based, multi-modal texts as well. Readers navigate print-based multi-modal texts (e.g. textbooks or picture books) and screen-based multi-modal texts based on their purposes for reading and the meanings readers construct in their transactions with these texts.
The research on the decoding of written texts refers to a series of cognitive strategies or skills, including word recognition, vocabulary knowledge, sound (phoneme) to symbol (grapheme) correspondence and the recognition of patterns in spelling and language to be successful (Bear, Invernizzi, Templeton, & Johnston, 2000; Dahl, 2001; Moustafa, 1997). When reading multi-modal texts, the skill of decoding written text needs to be accompanied by an understanding of the structures and codes associated with design, images and other visual elements (Kress & van Leeuwen, 1996). In addition to decoding written language, readers must learn to navigate the design of written text, including the left to right orientation of English language texts, and understand the role and structures of charts, graphs, diagrams and other visual images encountered in picture books, informational texts, graphic novels, websites, advertisements and other multi-modal texts.
In contrast to the temporal nature of the written language, there is no preset or determined path that readers are required to follow sequentially through multi-modal texts (Kress, 2003). Readers actively select objects from their visual field to attend to and interpret. A particular multi-modal text or visual image may contain compositional structures that lead a viewer's eye in certain directions, and certain features of visual grammar – for example, modality, framing and salience (Kress & van Leeuwen, 1996) – may draw one's attention to particular aspects of an image or multi-modal text; however, the reading path is ultimately determined by the readers during their transaction with the spatial composition of the text.
Focusing on visual images, Beardsley (1981) suggested:
a picture is two things at once: it is a design, and it is a picture of (italics in original) something. In other words, it presents something to the eye for direct inspection, and it represents something that exists, or might exist outside the picture frame. (p. 267)
What is presented to the eye for direct inspection or close attention are the literal or natural aspects of an image (Panofsky, 1955). Naming the visual elements of a multi-modal text, and taking an inventory of its contents, is primarily a perceptual act (Serafini, 2010). Readers navigating multi-modal texts must attend to, or perceive, what has been rendered by the artist, illustrator, publisher or graphic designer. The successful navigation of multi-modal texts is an important precursor of the interpretation of these texts.
Navigating multi-modal texts requires readers to attend to the grammars of visual design, in addition to the grammar, structures and typography associated with written language. The decoding processes outlined by Luke and Freebody (1999), for instance, delineate a reader's ability to break the code of written texts by recognizing and using fundamental features and architecture, including alphabet, sounds in words and spelling, and structural conventions and patterns may be subsumed within the larger concept of navigating. In addition, non-linear structures, hypertext, visual images and multi-modal compositional structures need to be navigated by readers if readers are to be successful in today's educational settings. Navigating, including the decoding of written text, is an important skill and an equally important consideration for literacy educators, but it is an insufficient skill in and of itself to make readers proficient in new times.
Reader as interpreter
Simply stated, readers as interpreters are readers engaged in the act or process of interpretation. Interpretation is a process of constructing or generating viable meanings and responses to various texts and images. Terms such as comprehending, understanding, constructing meaning and making sense are often used interchangeably to define the act of interpretation. Whatever term is selected, one of the primary goals of reading a multi-modal text or viewing a visual image is to understand or comprehend what has been written by the author or depicted by the artist (Goodman, 1996; Kress & van Leeuwen, 1996).
Interpretation is a contested concept. Various literary theories rely on different methods or processes of interpretation “because each has a different metaphysics, a different set of convictions that makes up its point of departure and defines its position in the hermeneutic field” (Armstrong, 1990, p. 4). Debates between monists, theorists that assert single, correct interpretations of a literary work discoverable by appealing to authorial intentions or close readings of the work itself, and pluralists, theorists that insist any text allows for an infinite array of legitimate readings, have challenged the notion of comprehension as an objective enterprise. If one aligns with Rorty's (1979) contention that there exists no single truth but always an array of interpretations, comprehension must be reconsidered as an act of interpretation, not as one of discovery of a single meaning or truth that exists a priori to the act of reading. The monist and pluralist theoretical positions may be incommensurable, but each relies on particular epistemological moves to “give momentary stability and coherence to what is dynamic, contradictory, and historical” (Solsken, 1993, p. 319).
Writing about Luke and Freebody's four resources model, Ludwig (2003) chooses the preposition from when describing the reader as text participant. She writes, “the emphasis is on comprehending and composing or making meaning from written, spoken, visual and multi-modal texts” (p. 1). The preposition from assumes that meaning is interred within the text and a meaning is discovered that exists a priori to the act of reading. Often times, the use of the preposition from connotes an objectivist conception of meaning, assuming meaning exists before the act of reading takes place and is to be discovered by the reader (Serafini, 2010). The preposition with could be used to connote a more constructivist stance in regard to the act or processes of reading.
In addition, the term comprehension connotes an objective perspective towards meaning making (Smagorinsky, 2001). It may be useful to reconsider the term comprehension (as noun), referring to a commodity or amount of information that is individually acquired through cognitive skill or work, or some measurable amount of knowledge or understanding that is literally taken away from every successful reading event. Instead, it may be more appropriate to consider the term comprehending (as verb), to refer to reading as a process, a recursive cycle of generating meanings that changes each time readers transact with a visual image of multi-modal text across particular contexts. This second definition, comprehending as verb, is closely associated with the concept and process of interpretation presented here. Interpretation is a construction of meaning drawing on one's prior knowledge and experiences the immediate and cultural contexts of the act of reading and the language and images presented for interpretation (Scholes, 2001).
Based on these theoretical assertions, readers should no longer be viewed as solitary explorers trying to uncover a single main idea hidden in the bowels of a classic novel or as “passive consumers of authoritative interpretations” (Faust, 1994, p. 25). Readers should be viewed as active constructors of meanings, transacting with texts in particular times, places and contexts (Rosenblatt, 1978). Readers come to the act of reading with their prior cultural, linguistic, literary and life experiences and draw upon these experiences as each reading is “situated in dialogue with and in extension of other readings” (Smagorinsky, 2001, p. 141). An expanded definition of reader as interpreter needs to address the processes of generating viable interpretations in transaction with visual images and written texts and one's ability to construct understandings from multiple perspectives, including the author's intentions, textual references, personal experiences and sociocultural contexts in which one reads (Serafini & Ladd, 2008).
This shift from comprehension to interpretation assumes an increase in authority or agency of the reader during the reading process. Readers as interpreters are constructors of meanings, drawing upon available resources to make sense of what is written or depicted. This is a shift away from what is referred to as an autonomous model of literacy (Street, 1984) or as a conduit model of reading (Mosenthal, 1987) where meanings exist a priori and are simply presented to readers through a text serving as a neutral channel or conduit.
When considering the images, text and design elements contained in multi-modal texts, it should be made clear that images are not neutral, objective representations of reality anymore than language is a neutral, objective representation of reality (Gombrich, 1961; Rorty, 1979). Viewers of design elements and visual images, like readers of written texts, are socialized into ways of seeing, in much the same way that readers are socialized into particular ways of reading (Berger, 1972).
A visual image, like a written text, does not exist nor is it created in a vacuum. An image, like any written text, “is not a unitary, seamless whole, but can be fragmented and atomized into constituent elements, and these elements represent a life of their own and that of others” (Hartman, 1992, p. 297). Readers draw upon a wide range of experiences with other images and texts during their act of interpretation. The unique personal experiences of each individual reader add to the variations inherent in one's interpretations. In similar fashion, the experiences one has in common with other members of a culture, society or community of readers add to the commonalities of interpretations across individual readers (Fish, 1980).
The process of interpreting multi-modal texts requires readers to draw from their experiential reservoirs to generate viable interpretations to add to the interpretations made by others in a community of readers regardless of one's allegiance to any single literary theory. Freebody's (1992) original conception of reader as text participant included knowledge of “the resources to engage in the technology of the text itself – its meaning and structure” (p. 53) and conceived of the reader as an “inferrer of connections between textual elements and of additional material required to fill out the unexplicated aspects of text” (p. 53). Luke and Freebody (1999) extended their definition of reader as text participant to include participation in understanding and composing meaningful written, visual and multi-modal texts, taking into account each text's interior meaning systems in relation to their available knowledge and their experiences of other cultural discourses, texts and meaning systems.
The interpretation of multi-modal texts requires readers to develop interpretive repertoires that address the visual images and design elements, in addition to the text itself, and the meaning potential across the various modes presented. Drawing on social semiotics (van Leeuwen, 2005), multi-modal analysis (Kress, 2010; Machin, 2007), iconography (Panofsky, 1955) and art theory (Gombrich, 1961), the interpretation of visual images and design can be conceived as a tripartite or three-tiered interpretive framework that requires attention to the perceptual, structural and ideological aspects of multi-modal texts (Serafini, 2010). The images contained in multi-modal texts encountered in complex social contexts are created with particular semiotic resources, basic design elements and visual structures. To expand one's interpretive repertoires to include approaches to visual analysis, readers will be required to synthesize perceptual abilities with structural perspectives and political, historical and cultural understandings. The act of interpreting may focus on the construction of knowledge by individual readers, but must also account for the sociocultural contexts of production, as well as reception, of multi-modal texts.
Reader as designer
Reader as designer extends the constructivist metaphor (Spivey, 1997) or role of reader as text participant to assert that readers of multi-modal texts not only construct meaning from what is depicted or represented, but also design the way the text is read, its reading path, what is attended to and, in the process, construct a unique experience during their transaction with a text. Reader as designer goes beyond the classic constructivist metaphor that asserts readers construct meaning from a text that exists a priori, to suggest readers actually construct the text to be read. From a literary theoretical perspective, this concept of constructing meaning associated with reader as designer goes beyond the reception theory of Iser (1978) and aligns more closely with Fish's (1980) notion of interpretive communities positing there is no immanent meaning in text and suggests readers decide not only what texts mean, but what can be considered a text.
Beginning with James' (1978) notion of selective attention and progressing through contemporary theories of multi-modality (Kress, 2010), a contemporary definition of the term design refers to “the process of translating the rhetor's politically oriented assessment of the environment of communication into semiotically shaped material” (Kress, 2010, p. 132). A general principle of semiosis, in particular a principle of design, is the process of transformation (Kress & van Leeuwen, 2001). Readers design texts to be navigated and interpreted by drawing upon the available semiotic resources presented in a text and construct meanings during the act of reading. Design is the process of organizing what is to be navigated, interpreted and articulated, shaping available resources into potential meanings realized in the context of reading multi-modal texts. In other words, the text to be read does not come to the reader ready-made; the text comes as semiotic potential, where the text to be interpreted is designed during the act of reading.
Up to this point, design has been primarily conceived from the perspective of the writer, creator or rhetor in Kress' terms (Kress, 2010). The designer of a text imagines the task at hand, uses his/her knowledge of available semiotic resources, understands the wider social conditions of production and reception and produces a text by selecting a site of appearance for the materialization of its intended meanings (Kress, 2010). The New London Group (1996) suggested educators “treat any semiotic activity, including language to produce or consume texts, as a matter of Design” (p. 74). Their concept of design involved the transformation, not replication, of available designs, suggesting that meaning is constructed anew in each act of reading (interpreting) or authoring (producing) texts, while at the same time reconstructing and renegotiating the reader's identity. Hull and Nelson (2005) write, “it is obvious how useful the notion of design can become as a way to conceptualize the suddenly increased array of choices about semiotic features that an author confronts” (p. 229). What may not be as obvious is the way that design plays a role in the way a reader constructs the reading paths, the array of choices of semiotic features and, in essence, the texts being read.
The concept of reader as designer can be extended from the producer of texts to the process of navigating and interpreting multi-modal texts as well. Making a shift from designer as producer of multi-modal texts to navigator, interpreter of texts requires an expansion of the concept of design to include the active construction of meaning potentials during reader's transactions with multi-modal texts. Unlike traditional written text that is presented in a linear, temporal sequence, where the reading path is ordered a priori, multi-modal and hypertexts are often presented in non-linear fashion. For example, postmodern picture books (Sipe & Pantaleo, 2008) require readers to not only navigate the visual and textual elements presented during the act of reading, but to actually design the text to be read from the visual and textual elements. Like the traditional “choose your own adventure texts”, the reader is required to become an even more active participant in the navigation, interpretation and design of multi-modal texts.
Numerous reading paths are possible given the compositional nature and spatial arrangements of multi-modal texts (Kress, 2010). However, the paths chosen by readers are not arbitrary, nor are they predetermined by the artist or graphic designer, though these creators draw upon various compositional, visual, design and typographical features to suggest how a text may be read. The interests, needs and experiences of the reader motivate which paths are selected. In this sense, the concept of design provides the reader with agency as he/she constructs meaning from the available semiotic resources presented in the multi-modal text.
Kress and van Leeuwen (2001) suggest contemporary or multi-modal texts ask readers to perform a different semiotic work, namely to design the order of the text or reading path for themselves before interpreting the text constructed. This semiotic work requires readers to make choices about how to frame the text being read. Whereas the process of navigation requires the reader to navigate the design elements of the text presented by the author-illustrator-publisher, the process of design requires the readers to construct their own reading path by framing the elements of a multi-modal text to suit their particular needs and interests during the act of reading. Navigating the elements presented by the author-illustrator-publisher and making decisions about the sequence of elements considered should be considered acts of design, utilizing the semiotic resources available to construct meaning in transaction with the elements of these texts.
As compared with the temporal or linear composition of written language, the spatial composition of visual and multi-modal texts presents readers with a less directed, more open reading path. This openness requires readers to design the path through which their reading occurs. Similar to Rosenblatt's (1978) concept of evocation, the reader of multi-modal texts must evoke or design the text to be read before it can be interpreted. The shift from the dominance of linear, print-based texts to visual and multi-modal texts requires a more active process on behalf of the reader and less authority and direction by the author-illustrator-publisher (Kress, 2010).
An additional aspect of reader as designer is the concept of framing (Kress & van Leeuwen, 1996). Readers construct frames around experience to organize encounters with the world, in particular with multi-modal texts, to make sense of these texts and consider them in the contexts in which they are realized. Without a frame, there is no meaning potential since all meaning is constructed within a discourse or other framing device. Frames mark both temporal and spatial locations. They separate the text being read from the context in which it is read. The reader decides on what is part of the text and what is part of the context to be considered when reading.
Framing devices include, as well as exclude, aspects of the world or text to be considered. The act of framing decides the aspects of the text to be considered in accordance with the interests of the framer (Kress, 2010). In other words, the reader makes decisions about which aspects of the texts are being navigated to consider and interpret and, in doing so, designs the text to be read, rather than passively uncovering a text that comes to the reader ready-made according to the ministrations of the author, illustrator/designer or publisher. For Kress (2010), this is the inherent difference between the world ordered for the reader and the world designed by the reader. The reader as designer selects from all the possible ways of positioning a text, the various design, visual and textual elements presented and the sociocultural contexts of the act of reading and decides on how a particular text is to be read in a particular time and place.
Reader as interrogator
Understanding the social practice of reader as interrogator requires a shift from a primarily cognitive theory of reading (Anderson & Pearson, 1984) to consider cultural theories of meaning (Smagorinsky, 2001). Cultural theories of meaning assume a reading of a text to have idiosyncratic (personal) as well as culturally mediated (public) meanings. From this perspective, reading is re-conceptualized as a social practice that involves the construction of meaning in a socially mediated context, the power relationships inherent in any given setting and the readers' identity and available means of social participation. Although the term interrogator was chosen rather than the term analyst to connote a more aggressive stance to interpreting and designing texts, the two concepts are closely aligned. The concept of interrogator, like that of text analyst, includes the critical and sociocultural aspects of analysis espoused by Luke and Freebody in their original four resources model.
Meanings constructed during the act of reading are socially embedded, temporary, partial and plural (Corcoran, Hayhoe, & Pradl, 1994). Texts are not interpreted by readers in a vacuum, but are always read by particular readers, in particular contexts, written by particular authors, containing an array of semiotic resources, including written language, visual images and design elements (Lewis, 2000). Additionally, different readings, meanings and interpretations have material, discursive and sociocultural consequences for readers. Working from a poststructuralist or critical perspective, the meanings constructed in transaction with multi-modal texts are social, historical, partial, multiple and political (Brodkey, 1992). In other words, if the reading of a multi-modal text requires the text to be framed or designed in a particular way, the text can be framed in other ways and each frame has significant consequences for the reader.
Research from a sociocultural or critical perspective focuses on the types of meanings that readers construct, how these meanings are affected by the social context and reading practices that readers are located within and the purposes of constructing particular responses (Gee, 1992; John-Steiner, Petoskey, & Smith, 1994). Readers construct readings (plural), not as originators of meaning, but as human subjects positioned through social, political and historical practices that remain the location of a constant struggle over power.
Visual grammar, iconology and media studies suggest readers analyse texts at the site of production, image and reception or audience (Rose, 2001). Where cognitive theories of reading focus primarily on the site of reception, the reader as interrogator must consider the production of images and multi-modal texts and the intended audiences for such texts when constructing meanings during the act of reading. “To explore the meaning of images is to recognize that they are produced within a system of social power and ideology. Ideologies are systems of belief that exist within all cultures” (Sturken & Cartwright, 2001, p. 21). They continue, “images are an important means through which ideologies are produced and onto which ideologies are projected” (p. 21). Rose (2001) argues, “one of the central aims of ‘the cultural turn’ in the social sciences is to argue that social categories are not natural but instead are constructed. These constructions can take visual form” (pp. 10–11). The interrogation of the visual images and elements of multi-modal texts, including borders, fonts, graphic design and colour, is just as important as the analysis of the written text.
To understand the images and design elements presented in multi-modal texts requires readers to consider aspects of production and reception, in addition to the aspects of the image and text itself. The capacity of images to affect us as viewers is dependent on the larger cultural meanings they evoke and the social, political and cultural contexts in which they are viewed (Sturken & Cartwright, 2001). Wolcott (1996) argues that readers must look not only at the relationships within a work of art but beyond the work itself to the historical, cultural and social contexts in order to comprehend its meaning.
Moving beyond the literal level of meaning requires readers to infer from various texts and contexts to interrogate what they read and view (Serafini & Ladd, 2008). Every classroom is a site for the production of meaning, and every interpretive community has some alignment with a particular literary tradition or perspective (Fish, 1980). Helping readers interrogate the meaning potential of the semiotic and multi-modal resources of a text is an important consideration in today's educational environment.
Concluding remarks
There are numerous theoretical and pedagogical challenges that arise in expanding the four resources or social practices model for reading multi-modal texts. The first challenge in constructing separate resources or practices is the distinctions between the four new resources or reading practices are blurred. How does one perceive and navigate the visual images and design of multi-modal texts without constructing meaning and having a set purpose for reading? How does a reader design the texts being read without analysing them simultaneously? These four expanded resources, although presented as four distinct resources for reading, are interrelated and inseparable in the act of reading–viewing. Freebody and Luke (1990) stated that each resource or practice was necessary but insufficient and that no single resource was sufficient in and of itself for being successful in today's societies. The same holds true for the four resources described for reading multi-modal texts.
A second challenge is the social practices for reading multi-modal texts themselves do not emerge a priori; these practices are constructed by readers in the same way as the earlier practices were constructed in sociocultural, historical, political and economic contexts. In addition, viewers of images, like readers of written texts, have agency in their creation of these practices and their use of these interpretive and analytic strategies and processes. The four multi-modal practices are adapted, not simply adopted, by readers as they transact with the texts and images in the various contexts in which they are encountered.
A third challenge arises in trying to avoid describing the four resources model hierarchically. Rather than conceptualizing the four resources as a hierarchical set of competencies, the four practices are “nested” within one another, influencing each other and blurring the distinctions between the various perspectives or practices described (Serafini, 2010). Freebody and Luke (2003) consider the four resources model a “systematic way of interrogating practice” (p. 57) with each resource contributing to the reading process in its own unique way.
By expanding the dimensions we bring to interpreting and understanding multi-modal texts, we widen the scope of inquiry to include perceptual and cognitive perspectives, in addition to sociocultural and critical theoretical and analytical perspectives. The power of the four resources model was its inclusion of different theoretical perspectives, not in its exclusion. The role of progressive literacy education is to open up the interpretive spaces we provide through the expectations we set, the responses we endorse and support, the texts we select to expand readers' interpretive repertoires and the strategies we demonstrate during reading instruction (Serafini, 2011).
References
- 1. Albers, P. 2008. Theorizing visual representation in children's literature. Journal of Literacy Research, 40(2): 163–200. [CrossRef], [Web of Science ®]
- 2. Anderson, R.C. and Pearson, P.D. 1984. “A schema-theoretic view of basic processes in reading comprehension”. In The handbook of reading research: Vol 1, Edited by: Pearson, P.D., Barr, R., Kamil, M. and Mosenthal, P. 255–291. New York, NY: Longman.
- 3. Anstey, M. and Bull, G. 2004. The literacy labyrinth, 2nd, Sydney: Pearson Education.
- 4. Anstey, M. and Bull, G. 2006. Teaching and learning multiliteracies: Changing times, changing literacies, Newark, DE: International Reading Association.
- 5. Arizpe, E. and Styles, M. 2003. Children reading pictures: Interpreting visual texts, New York, NY: Routledge.
- 6. Armstrong, P.B. 1990. Conflicting readings: Variety and validity in interpretation, Chapel Hill: University of North Carolina Press.
- 7. Baldry, A. and Thibault, P.J. 2006. Multimodal transcription and analysis: A multimedia toolkit and coursebook, London: Equinox.
- 8. Barnard, M. 2001. Approaches to understanding visual culture, New York, NY: Palgrave.
- 9. Bateman, J.A. 2008. Multimodality and genre: A foundation for the systematic analysis of multimodal documents, New York, NY: Palgrave Macmillan. [CrossRef]
- 10. Bear, D.R., Invernizzi, M., Templeton, S. and Johnston, F. 2000. Words their way: Word study for phonics, vocabulary, and spelling instruction, Upper Saddle River, NJ: Prentice-Hall.
- 11. Beardsley, M.C. 1981. Aesthetics: Problems in the philosophy of criticism, Indianapolis, IN: Hackett Publishing.
- 12. Berger, J. 1972. Ways of seeing, London: Penguin.
- 13. Brodkey, L. 1992. “Articulating poststructural theory in research on literacy”. In Multidisciplinary perspectives on literacy research, Edited by: Beach, R., Green, J., Kamil, M. and Shanahan, T. 293–318. Urbana, IL: National Council of Teachers of English.
- 14. Callow, J. 1999. Image matters: Visual texts in the classroom, Marrickville, NSW: Primary English Teaching Association.
- 15. Corcoran, B., Hayhoe, M. and Pradl, G.M., eds. 1994. Knowledge in the making: Challenging the text in the classroom, Portsmouth, NH: Boynton-Cook.
- 16. Dahl, K.L. 2001. Rethinking phonics: Making the best teaching decisions, Portsmouth, NH: Heinemann.
- 17. Faust, M. 1994. “Alone but not alone: Situating readers in school contexts”. In Knowledge in the making: Challenging the text in the classroom, Edited by: Corcoran, B., Hayhoe, M. and Pradl, G.M. 25–33. Portsmouth, NH: Boynton-Cook.
- 18. Fish, S. 1980. Is there a text in this class? The authority of interpretive communities, Cambridge, MA: Harvard University Press.
- 19. Fleckenstein, K.S. 2002. “Inviting imagery into our classrooms”. In Language and images in the reading-writing classroom, Edited by: Fleckenstein, K.S., Calendrillo, L.T. and Worley, D.A. 3–26. Mahwah, NJ: Lawrence Erlbaum Associates.
- 20. Freebody, P. 1992. “A socio-cultural approach: Resourcing four roles as a literacy learner”. In Prevention of reading failure, Edited by: Watson, A. and Beadenhop, A. 48–80. Sydney, NSW: Ashton-Scholastic.
- 21. Freebody, P. 2007. Literacy education in school: Research perspectives from the past, for the future, Camberwell, VIC: Australian Council for Educational Research.
- 22. Freebody, P. and Luke, A. 1990. Literacies programs: Debates and demands in cultural context. Prospect: Australian Journal of TESOL, 5(7): 7–16.
- 23. Freebody, P. and Luke, A. 2003. “Literacy as engaging with new forms of life: The “four roles” model”. In The literacy lexicon, 2nd, Edited by: Bull, G. and Anstey, M. 51–66. Frenchs Forest, NSW: Pearson Education.
- 24. Gee, J.P. 1992. Socio-cultural approaches to literacy (literacies). Annual Review of Applied Linguistics, 12: 31–48. [CrossRef], [CSA]
- 25. Gee, J.P. 1996. Social linguistics and literacies: Ideology in discourses, London: Taylor & Francis.
- 26. Gombrich, E.H. 1961. Art and illusion: A study in the psychology of pictorial representation, 2nd, Princeton, NJ: Princeton University Press.
- 27. Goodman, K. 1996. On reading: A common-sense look at the nature of language and the science of reading, Portsmouth, NH: Heinemann.
- 28. Gough, P.B. 1972. One second of reading. Visible Language, 6(4): 291–320. [CSA]
- 29. Hartman, D.K. 1992. Intertextuality and reading: The text, the reader, that author, and the context. Linguistics and Education, 4: 295–311. [CrossRef], [CSA]
- 30. Henderson, J. 1992. Anabranch or billabong? The evaluation of reading programs offered to unsuccessful readers during middle primary school years. The Australian Journal of Language and Literacy, 16(2): 119–135. [CSA]
- 31. Hull, G.A. and Nelson, M.E. 2005. Locating the semiotic power of multimodality. Written Communication, 22(2): 224–261. [CrossRef], [Web of Science ®]
- 32. Iser, W. 1978. The act of reading, Baltimore, MD: Johns Hopkins University Press.
- 33. James, W. 1978. Essays in philosophy, Cambridge, MA: Harvard University Press.
- 34. Jewitt, C., ed. 2009. The Routledge handbook of multimodal analysis, London: Routledge.
- 35. John-Steiner, V., Petoskey, C. and Smith, L. 1994. Sociocultural approaches to language and literacy, New York, NY: Cambridge University Press. [CrossRef]
- 36. Kress, G. 2003. Literacy in the new media age, London: Routledge. [CrossRef]
- 37. Kress, G. 2010. Multimodality: A social semiotic approach to contemporary communication, London: Routledge.
- 38. Kress, G. and van Leeuwen, T. 1996. Reading images: The grammar of visual design, London: Routledge Falmer.
- 39. Kress, G. and van Leeuwen, T. 2001. Multimodal discourse: The modes and media of contemporary communication, London: Edward Arnold.
- 40. Lawless, K.A. and Schrader, P.G. 2008. “Where do we go now? Understanding research on navigation in complex digital environments”. In Handbook of research on new literacies, Edited by: Coiro, J., Knobel, M., Lankshear, C. and Leu, D.J. 267–296. New York, NY: Lawrence Erlbaum Associates.
- 41. Lewis, C. 2000. Limits of identification: The personal, pleasurable, and critical in reader response. Journal of Literacy Research, 32: 253–266. [CrossRef], [Web of Science ®]
- 42. Ludwig, C. (2003). Making sense of literacy. Newsletter of the Australian Literacy Educators' Association. http://www.alea.edu.au/documents/item/53 (http://www.alea.edu.au/documents/item/53)
- 43. Luke, A. 1995. When basic skills and information processing just aren't enough: Rethinking reading in new times. Teachers College Record, 97(1): 95–115. [Web of Science ®], [CSA]
- 44. Luke, A. and Freebody, P. 1997. “Shaping the social practices of reading”. In Constructing critical literacies: Teaching and learning textual practice, Edited by: Muspratt, S., Luke, A. and Freebody, P. 185–225. Cresskill, NJ: Hampton Press.
- 45. Luke, A., & Freebody, P. (1999). Further notes on the four resources model. Reading Online. http://www.readingonline.org/research/lukefreebody.html (http://www.readingonline.org/research/lukefreebody.html)
- 46. Machin, D. 2007. Introduction to multimodal analysis, London: Hodder Arnold.
- 47. Mosenthal, P. 1987. Meaning in the storage-and-conduit metaphor of reading. The Reading Teacher, 41(3): 340–342. [Web of Science ®]
- 48. Moustafa, M. 1997. Beyond traditional phonics: Research discoveries and reading instruction, Portsmouth, NH: Heinemann.
- 49. New London Group. 1996. A pedagogy of multiliteracies: Designing social futures. Harvard Educational Review, 66(1): 60–92. [CrossRef], [Web of Science ®], [CSA]
- 50. Panofsky, E. 1955. Meaning in the visual arts, Chicago, IL: University of Chicago Press.
- 51. Pressley, M. and Block, C.C. 2001. Comprehension instruction: Research-based best practices, New York, NY: Guilford.
- 52. Rorty, R. 1979. Philosophy and the mirror of nature, Princeton, NJ: Princeton University Press.
- 53. Rose, G. 2001. Visual methodologies, London: Sage.
- 54. Rosenblatt, L. 1978. The reader, the text, the poem: The transactional theory of the literary work, Carbondale: Southern Illinois University Press.
- 55. Scholes, R. 1982. Semiotics and interpretation, New Haven, CT: Yale University Press.
- 56. Scholes, R. 2001. The crafty reader, New Haven, CT: Yale University Press.
- 57. Semali, L. 2003. Ways with visual languages: Making the case for critical media literacy. The Clearing House, 39(3): 271–277. [Taylor & Francis Online]
- 58. Seppanen, J. 2006. The power of the gaze: An introduction to visual literacy, New York, NY: Peter Lang.
- 59. Serafini, F. 2010. Reading multimodal texts: Perceptual, structural and ideological perspectives. Children's Literature in Education, 41: 85–104. [CrossRef], [Web of Science ®]
- 60. Serafini, F. 2011. Expanding perspectives for comprehending visual images in multimodal texts. Journal of Adolescent & Adult Literacy, 54(5): 342–350. [CrossRef], [Web of Science ®]
- 61. Serafini, F. and Ladd, S.M. 2008. The challenge of moving beyond the literal in literature discussions. Journal of Language and Literacy Education, 4(2): 6–20.
- 62. Siegel, M. 2006. Rereading the signs: Multimodal transformations in the field of literacy education. Language Arts, 84(1): 65–77.
- 63. Sipe, L.R. 1998. How picture books work: A semiotically framed theory of text-picture relationships. Children's Literature in Education, 29(2): 97–108. [CrossRef], [Web of Science ®]
- 64. Sipe, L.R. and Pantaleo, S., eds. 2008. Postmodern picture books: Play, parody, and self-referentiality, New York, NY: Routledge.
- 65. Smagorinsky, P. 2001. If meaning is constructed, what is it made from? Toward a cultural theory of reading. Review of Educational Research, 71(1): 133–169. [CrossRef], [Web of Science ®]
- 66. Smith-Shank, D.L., ed. 2004. Semiotics and visual culture: Sights, signs, and significance, Reston, VA: National Art Education Association.
- 67. Snow, C. and Sweet, A. 2003. Rethinking reading comprehension, New York, NY: Guilford.
- 68. Solsken, J.W. 1993. The paradigm misfit blues. Research in the Teaching of English, 27(3): 316–325. [Web of Science ®]
- 69. Spivey, N.N. 1997. The constructivist metaphor: Reading, writing, and the making of meaning, San Diego, CA: Academic Press.
- 70. Street, B. 1984. Literacy in theory and practice, Cambridge: Cambridge University Press.
- 71. Sturken, M. and Cartwright, L. 2001. Practices of looking: An introduction to visual culture, Oxford: Oxford University Press.
- 72. Unsworth, L. and Wheeler, J. 2002. Re-valuing the role of images in reviewing picture books. Reading, 36(2): 68–74. [CrossRef]
- 73. van Leeuwen, T. 2005. Introducing social semiotics, London: Routledge.
- 74. Walsh, M. 2006. The “textual shift”: Examining the reading process with print, visual and multimodal texts. Australian Journal of Language and Literacy, 29(1): 24–37.
- 75. Whitaker, L.A. 1998. “Human navigation”. In Human factors and web development, Edited by: Forsythe, C., Grose, E. and Ratner, J. 63–74. Mahwah, NJ: Lawrence Erlbaum Associates.
- 76. Wolcott, A. 1996. Is what you see what you get? A postmodern approach to understanding works of art. Studies in Art Education, 37(2): 69–79. [CrossRef]
- 77. Zammit, K. 2007. “Popular culture in the classroom: Interpreting and creating multimodal texts”. In Advances in language and education, Edited by: McCabe, A., 'Donnell, M. O and Whittaker, R. 61–76. New York, NY: Continuum.
- 78. Zammit, K. and Downes, T. 2002. New learning environments and the multiliterate individual: A framework for educators. Australian Journal of Language and Literacy, 25(2): 25–36.
